# 이 장에서 사용하는 패키지
library(tidyverse) # 데이터 처리 및 시각화
library(gt) # 출판 품질 테이블
library(gtsummary) # 요약 통계 테이블
library(survival) # 생존분석 (Kaplan-Meier)
library(survminer) # 생존분석 시각화
library(broom) # 모델 결과 정리
library(patchwork) # 그래프 조합
library(scales) # 축 스케일링11 약력학 데이터 분석의 고려사항
이전 장에서 PK-PD 관계의 기본 개념과 모델을 학습했습니다. 이 장에서는 실제 약력학(PD) 데이터를 분석할 때 마주하는 실무적 고려사항을 심도 있게 다룹니다. Baseline 보정, placebo 효과 처리, 결측 데이터 전략, 피부과 PD 평가 도구의 상세한 계산 방법, 그리고 R을 활용한 PD 데이터의 다양한 분석 기법을 학습합니다.
피부과 임상시험에서 PD 엔드포인트는 PASI, EASI, IGA 등 반주관적(semi-objective) 평가 도구에 크게 의존합니다. 이러한 평가 도구의 특성을 깊이 이해하고, 데이터의 특수성에 맞는 분석 전략을 수립하는 것은 신뢰할 수 있는 PK-PD 분석의 필수 전제입니다.
11.1 PD 데이터의 특수성
11.1.1 PK 데이터와 PD 데이터의 차이
PK 데이터(혈중 농도)와 PD 데이터(약리학적 효과)는 본질적으로 다른 특성을 가지며, 이에 따라 분석 접근법도 달라야 합니다.
| 특성 | PK 데이터 | PD 데이터 |
|---|---|---|
| 측정 방법 | 객관적 (LC-MS/MS 등) | 반주관적 또는 주관적 |
| 데이터 유형 | 연속형 (농도) | 연속형, 순서형, 이분형 다양 |
| 측정 변이 | 분석 오차 (CV 5-15%) | 평가자 변이 + 생물학적 변이 (CV 20-50%+) |
| 기저값 의존성 | 일반적으로 없음 (0에서 시작) | 강한 baseline 의존성 |
| Placebo 효과 | 없음 | 상당한 placebo response 존재 |
| 시간 해상도 | 고빈도 (시간 단위) | 저빈도 (주-월 단위) |
| 결측 패턴 | Random (채혈 실패) | Informative (중도탈락과 연관) |
| 분포 | 로그정규분포 | 질환/평가 도구에 따라 다양 |
이러한 차이 때문에 PK 분석에서 통용되는 방법론을 PD 데이터에 그대로 적용하면 편향(bias)이나 잘못된 결론에 이를 수 있습니다.
11.1.2 Baseline 보정 방법
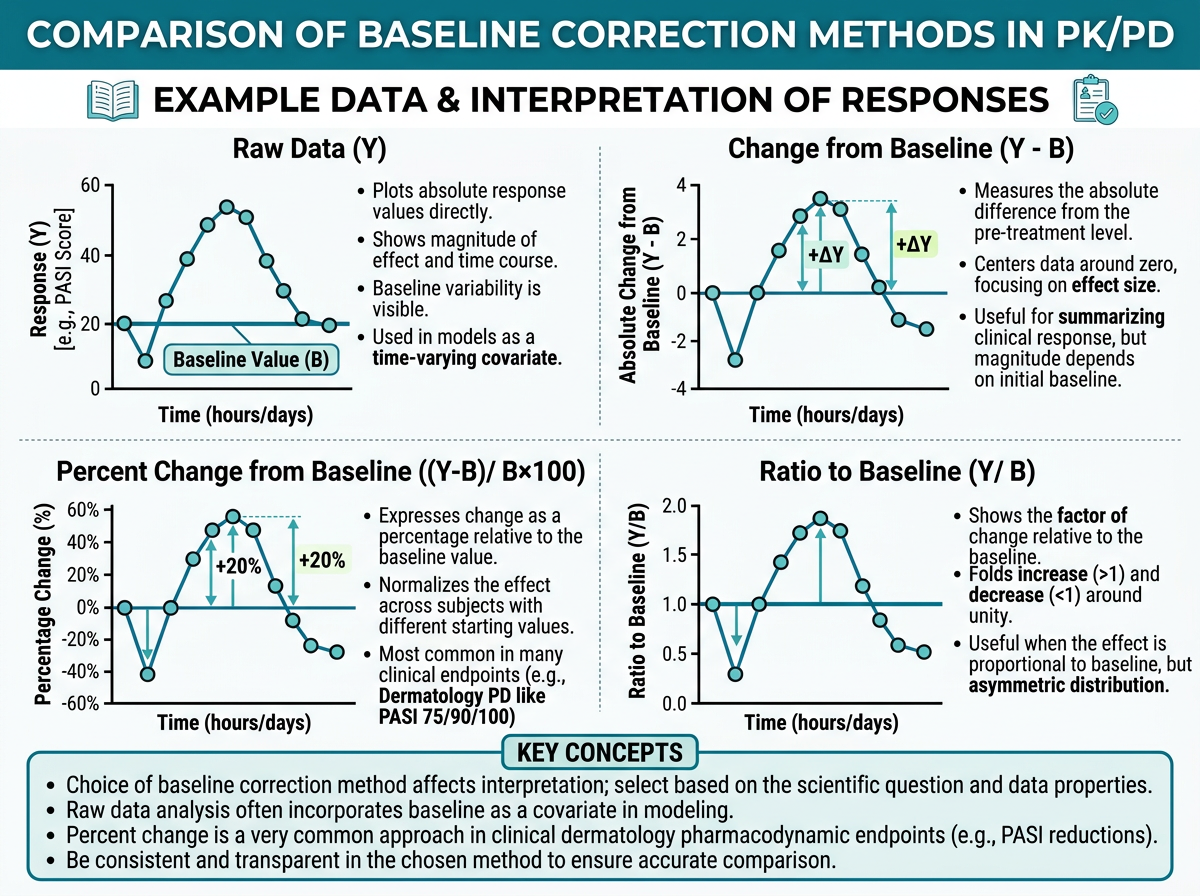
그림 11.1 는 동일한 데이터에 서로 다른 baseline 보정 방법을 적용한 결과를 비교한 것입니다. PD 데이터 분석에서 가장 먼저 결정해야 할 사항은 baseline 보정 방법입니다. 기저값(baseline)은 약물 투여 전 측정한 PD 값으로, 개인마다 다른 출발점을 가지므로 치료 효과를 공정하게 비교하려면 적절한 보정이 필수적입니다.
1. 절대 변화 (Absolute Change from Baseline)
\[\Delta = Y_{post} - Y_{baseline}\]
- 장점: 직관적이고 해석이 쉬움
- 단점: Baseline이 높은 환자에서 변화량이 크게 나타나는 경향 (ceiling/floor effect)
- 적용: Baseline 값의 범위가 좁고, 변화량 자체가 임상적 의미를 가질 때
- 예: DLQI 점수 변화, NRS pruritus 점수 변화
2. 백분율 변화 (Percent Change from Baseline)
\[\%\Delta = \frac{Y_{post} - Y_{baseline}}{Y_{baseline}} \times 100\]
- 장점: Baseline 차이를 보정하여 비교 가능, 규제 기관에서 널리 사용
- 단점: Baseline이 0이거나 매우 낮으면 불안정, baseline이 낮은 환자에서 과장된 변화
- 적용: PASI75/90/100, EASI-75 등 피부과의 주요 엔드포인트
- 예: PASI 20 → 5 = -75% (PASI75 달성), PASI 4 → 1 = -75% (PASI75 달성이지만 임상적 의미가 다름)
3. 비율 (Ratio to Baseline)
\[R = \frac{Y_{post}}{Y_{baseline}}\]
- 장점: 로그 변환 시 정규분포에 근접, PK-PD 모델링에서 선호
- 단점: 해석이 직관적이지 않을 수 있음
- 적용: PK 파라미터처럼 로그정규분포를 따르는 바이오마커
- 예: 혈청 IgE 비율, 호산구 수 비율
4. ANCOVA 보정 (Analysis of Covariance)
\[Y_{post} = \beta_0 + \beta_1 \cdot \text{Treatment} + \beta_2 \cdot Y_{baseline} + \epsilon\]
- 장점: 통계적으로 가장 효율적이며, baseline 불균형을 보정
- 단점: 모델 가정(선형성, 등분산성)이 필요
- 적용: 규제 기관에서 추천하는 방법, primary analysis에 사용
- EMA ICH E9(R1) 가이드라인에서 권장
중요Baseline 보정 방법의 선택
Baseline 보정 방법은 분석 결과에 큰 영향을 미칠 수 있으며, 사전에 통계분석계획서(SAP)에서 명시해야 합니다.
일반적 가이드라인:
- Primary analysis: ANCOVA (baseline을 공변량으로 포함)
- Responder analysis: % change (예: PASI75 = 75% 이상 감소)
- PK-PD modeling: Ratio 또는 absolute change (모델 구조에 따라)
- 탐색적 분석: 여러 방법을 병행하여 일관성 확인
Baseline 값이 0인 환자(이미 “clear”인 환자)는 % change 계산이 불가능하므로, 이들을 제외하거나 별도 처리하는 규칙이 필요합니다.
11.1.3 Placebo 효과 고려
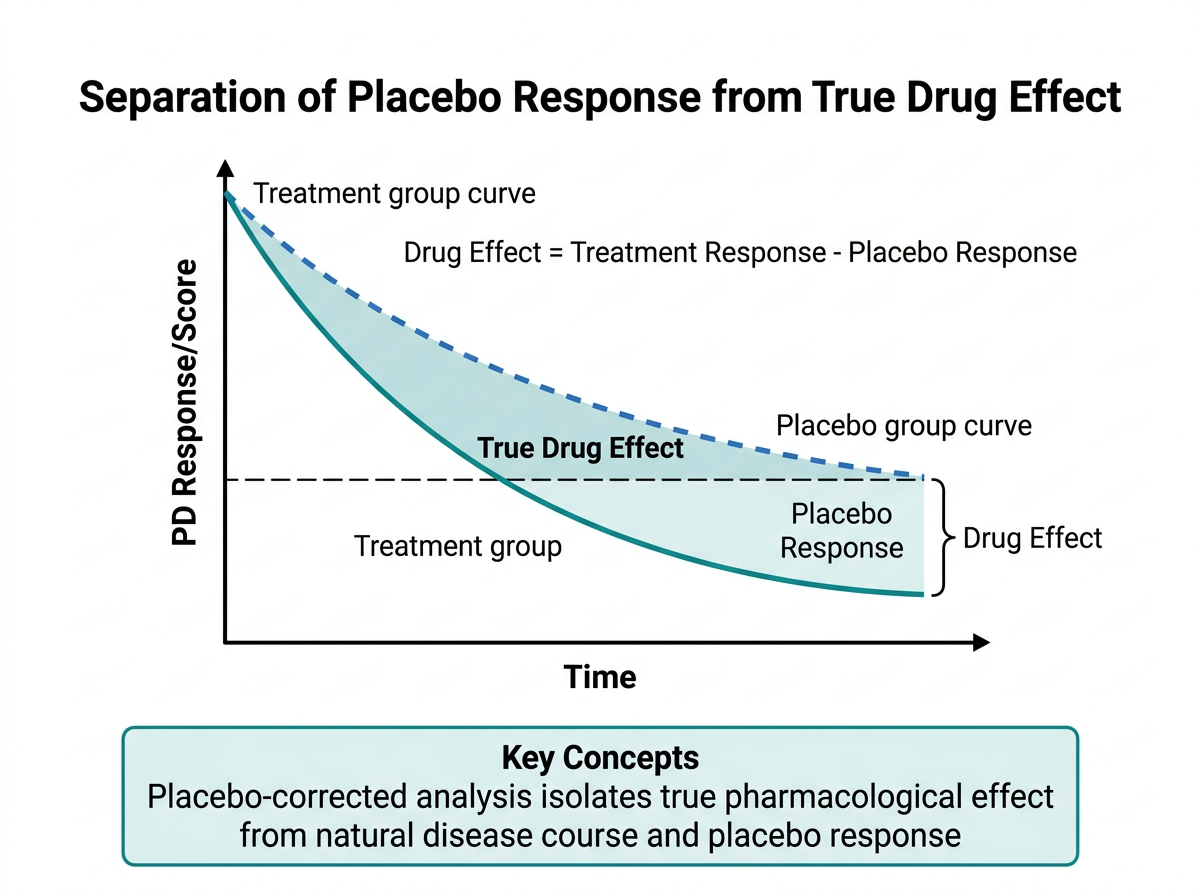
그림 11.2 에서 보듯이, 피부과 임상시험에서 placebo 효과(placebo response)는 상당히 크며, 이를 적절히 고려하지 않으면 약물의 진정한 효과를 과대평가할 수 있습니다.
피부과 임상시험에서의 Placebo Response 크기:
| 질환 | 엔드포인트 | Placebo Response | 약물 Response | 차이 |
|---|---|---|---|---|
| 건선 (중등증-중증) | PASI75 (12주) | 3-5% | 60-90% (biologics) | 큰 차이 |
| 아토피 피부염 | EASI-75 (16주) | 10-25% | 44-69% | 중등도 차이 |
| 아토피 피부염 | IGA 0/1 (16주) | 8-12% | 36-39% | 중등도 차이 |
| 두드러기 | UAS7 ≤6 (12주) | 15-25% | 40-60% | 중등도 차이 |
| 여드름 | IGA 0/1 (12주) | 10-20% | 25-45% | 작은 차이 |
Placebo Response의 원인:
- 자연 관해(Spontaneous remission): 질환의 자연 경과에 의한 호전
- 관찰 효과(Hawthorne effect): 관찰되고 있다는 인식에 의한 행동 변화
- Regression to the mean: Baseline이 높은 환자가 자연적으로 평균으로 회귀
- 보조 치료(Concomitant care): 보습제, 생활습관 개선 등의 동반 효과
- 평가자 편향(Rater bias): 시간 경과에 따른 평가 기준 변화
노트Placebo-adjusted Response
약물의 순수한 치료 효과를 추정하기 위해 placebo-adjusted response를 계산합니다:
\[\text{Placebo-adjusted} = \text{Drug response} - \text{Placebo response}\]
예: EASI-75 달성률이 약물군 51%, placebo군 15%일 때:
- 절대 차이: 51% - 15% = 36%p (percentage point)
- NNT (Number Needed to Treat): \(1 / 0.36 \approx 2.8\)명
PK-PD 모델링에서는 placebo 모델을 별도로 구축하여 drug effect와 placebo effect를 분리하는 접근이 사용됩니다.
11.1.4 자연 경과(Natural Course) 보정
만성 피부 질환은 시간에 따라 자연적으로 변동(fluctuation)합니다. 이러한 자연 경과를 모델에 포함하지 않으면 약물 효과를 과대 또는 과소 추정할 수 있습니다.
아토피 피부염의 자연 경과:
- 계절성 변동: 겨울에 악화, 여름에 호전 (일반적)
- 환경적 트리거: 스트레스, 알레르겐 노출에 따른 급성 악화
- 장기 경과: 일부 환자에서 나이에 따라 자연 관해
건선의 자연 경과:
- Koebner 현상: 피부 외상 후 악화
- 스트레스 관련 악화
- 감염(인두염 등) 후 급성 악화 (물방울 건선)
PK-PD 모델에서 자연 경과를 포함하는 방법:
\[\frac{dR}{dt} = k_{in}(t) \cdot (1 - I(C)) - k_{out} \cdot R\]
여기서 \(k_{in}(t)\)를 시간 의존적 함수로 만들어 질병의 자연 변동을 반영할 수 있습니다. 또는 별도의 disease progression model을 추가합니다.
11.1.5 결측 PD 데이터 처리 전략
PD 데이터의 결측은 PK 데이터의 결측과 달리 정보적 결측(informative missing)인 경우가 많습니다. 즉, 효과가 없거나 악화되어 중도탈락한 환자의 데이터가 빠지면 결과가 긍정적으로 편향됩니다.
주요 결측 데이터 처리 방법:
| 방법 | 설명 | 가정 | 보수성 |
|---|---|---|---|
| NRI (Non-Responder Imputation) | 결측 = 비반응으로 처리 | 가장 보수적 가정 | 매우 보수적 |
| LOCF (Last Observation Carried Forward) | 마지막 관측값 유지 | 변화 없음 가정 | 보수적-낙관적 (상황에 따라) |
| mBOCF (modified Baseline Observation CF) | 결측 시 baseline 값 적용 | 치료 효과 상실 가정 | 보수적 |
| MI (Multiple Imputation) | 통계적 대체 (반복) | MAR (Missing at Random) | 중립적 |
| MMRM (Mixed Model Repeated Measures) | 반복측정 혼합모델 | MAR | 중립적 |
| Tipping point analysis | 민감도 분석 | 다양한 시나리오 | 범위 제공 |
경고NRI와 mBOCF의 선택
FDA는 이분형 엔드포인트(PASI75, IGA 0/1 등)의 primary analysis에 NRI를 선호합니다. 이는 가장 보수적인 접근법으로, 약물 효과를 과대평가하지 않습니다. 그러나 NRI는 약물 효과를 과소평가할 수 있으며, 특히 비약물 관련 이유(이사, 일정 등)로 탈락한 환자를 비반응으로 처리하는 것은 불합리할 수 있습니다.
EMA는 MMRM 또는 MI를 선호하며, NRI를 민감도 분석으로 요구합니다. 따라서 글로벌 시험에서는 여러 방법을 병행하여 결과의 일관성을 확인하는 것이 표준입니다.
11.2 피부과 PD 평가 도구 상세
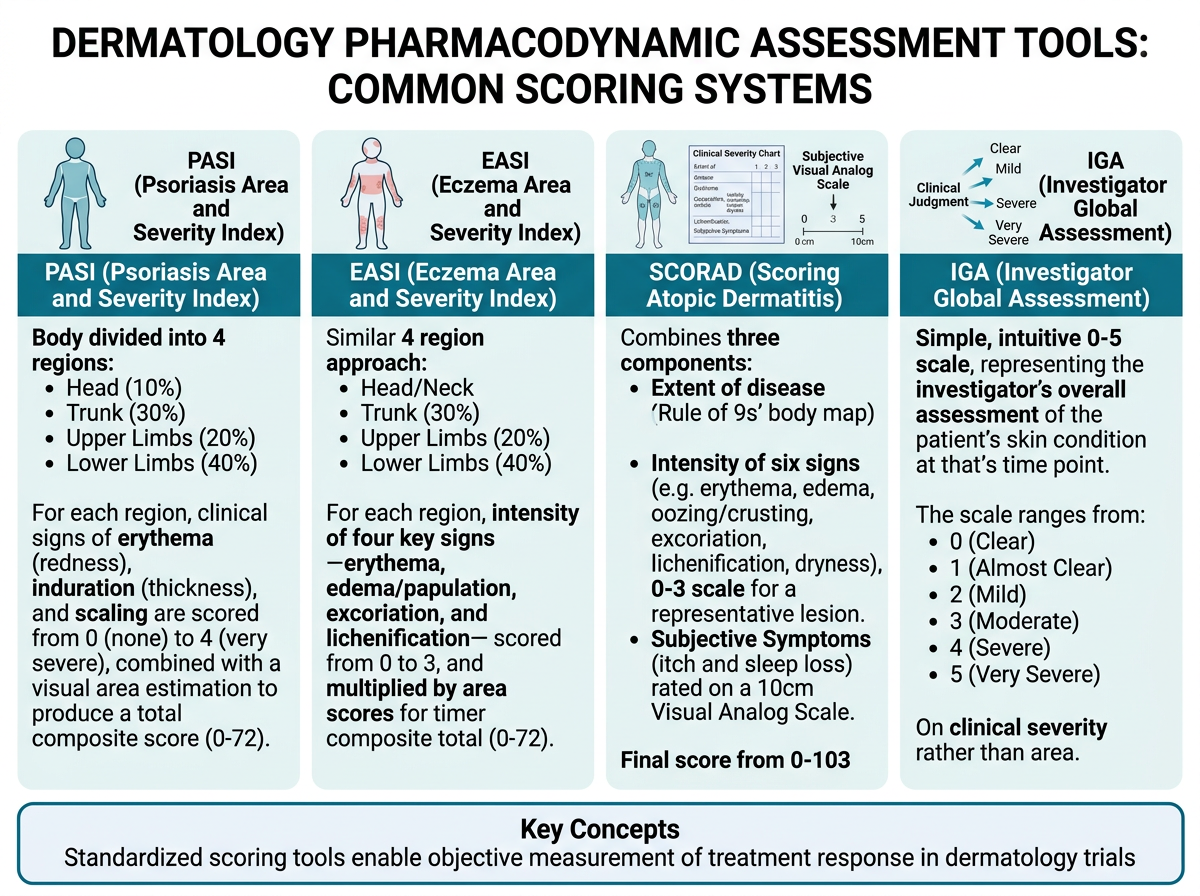
그림 11.3 은 피부과에서 널리 사용되는 PD 평가 도구(PASI, EASI, SCORAD, IGA)의 평가 체계를 비교한 것입니다.
11.2.1 PASI: Psoriasis Area and Severity Index
PASI는 건선의 중증도를 평가하는 gold standard 도구로, 1978년 Fredriksson과 Pettersson에 의해 개발되었습니다. 모든 건선 임상시험에서 primary 또는 co-primary endpoint로 사용됩니다.
PASI 계산 방법:
PASI는 신체를 4개 부위로 나누어 각각의 면적(area)과 중증도(severity)를 평가합니다.
| 신체 부위 | 약어 | 면적 가중치 | 전체 BSA 비율 |
|---|---|---|---|
| 두부 (Head) | h | 0.1 | ~10% |
| 상지 (Upper Limbs) | u | 0.2 | ~20% |
| 체간 (Trunk) | t | 0.3 | ~30% |
| 하지 (Lower Limbs) | l | 0.4 | ~40% |
각 부위의 평가 항목:
- 면적 점수 (Area Score, A): 0-6점
| 점수 | 병변 면적 비율 |
|---|---|
| 0 | 0% (병변 없음) |
| 1 | 1-9% |
| 2 | 10-29% |
| 3 | 30-49% |
| 4 | 50-69% |
| 5 | 70-89% |
| 6 | 90-100% |
- 중증도 점수 (Severity, 각 0-4점):
- 홍반 (Erythema, E): 0=없음, 1=경미, 2=중등, 3=심함, 4=매우 심함
- 경화/비후 (Induration/Thickness, I): 0-4
- 인설 (Desquamation/Scaling, D): 0-4
PASI 수식:
\[PASI = 0.1 \times A_h \times (E_h + I_h + D_h) + 0.2 \times A_u \times (E_u + I_u + D_u)\] \[+ 0.3 \times A_t \times (E_t + I_t + D_t) + 0.4 \times A_l \times (E_l + I_l + D_l)\]
- 최소값: 0 (완전 관해)
- 최대값: \(0.1 \times 6 \times 12 + 0.2 \times 6 \times 12 + 0.3 \times 6 \times 12 + 0.4 \times 6 \times 12 = 72\)
# PASI 계산 함수 구현
calculate_pasi <- function(
head_area, head_erythema, head_induration, head_scaling,
upper_area, upper_erythema, upper_induration, upper_scaling,
trunk_area, trunk_erythema, trunk_induration, trunk_scaling,
lower_area, lower_erythema, lower_induration, lower_scaling
) {
# 가중치
w <- c(head = 0.1, upper = 0.2, trunk = 0.3, lower = 0.4)
# 각 부위 점수
head_score <- w["head"] * head_area * (head_erythema + head_induration + head_scaling)
upper_score <- w["upper"] * upper_area * (upper_erythema + upper_induration + upper_scaling)
trunk_score <- w["trunk"] * trunk_area * (trunk_erythema + trunk_induration + trunk_scaling)
lower_score <- w["lower"] * lower_area * (lower_erythema + lower_induration + lower_scaling)
pasi <- head_score + upper_score + trunk_score + lower_score
return(as.numeric(pasi))
}
# 예시: 중등증 건선 환자
pasi_example <- calculate_pasi(
head_area = 2, head_erythema = 2, head_induration = 2, head_scaling = 2,
upper_area = 2, upper_erythema = 2, upper_induration = 2, upper_scaling = 1,
trunk_area = 3, trunk_erythema = 3, trunk_induration = 2, trunk_scaling = 2,
lower_area = 3, lower_erythema = 2, lower_induration = 2, lower_scaling = 2
)
cat("PASI Score:", pasi_example, "\n")
# 예상: 0.1*2*6 + 0.2*2*5 + 0.3*3*7 + 0.4*3*6 = 1.2 + 2.0 + 6.3 + 7.2 = 16.7PASI 반응 기준의 정의와 임상적 의미:
| 반응 기준 | 정의 | 임상적 의미 | 현재 위치 |
|---|---|---|---|
| PASI50 | ≥50% 감소 | 최소 유의한 개선, 과거 기준 | 보조 엔드포인트 |
| PASI75 | ≥75% 감소 | 임상적으로 유의한 개선 | 전통적 primary endpoint |
| PASI90 | ≥90% 감소 | 거의 완전 관해 | 최신 시험의 primary endpoint |
| PASI100 | 100% 감소 (PASI = 0) | 완전 관해 (clear skin) | Key secondary endpoint |
노트PASI75에서 PASI90으로의 패러다임 변화
과거에는 PASI75가 건선 치료 효과의 표준 기준이었습니다. 그러나 IL-17/IL-23 억제제와 같은 고효능 생물학적 제제의 등장으로 PASI75 달성률이 80-90%에 달하게 되면서, 약물 간 차별화가 어려워졌습니다. 이에 따라 최근 Phase III 시험에서는 PASI90 또는 PASI100을 primary endpoint로 채택하는 추세입니다.
예를 들어, Risankizumab vs Secukinumab 비교 시험(IMMerge)에서 52주 PASI90 달성률은 각각 87% vs 57%로, PASI90이 두 약물의 차이를 명확히 보여주었습니다.
11.2.2 EASI: Eczema Area and Severity Index
EASI는 아토피 피부염의 중증도를 평가하는 주요 도구로, PASI와 유사한 구조를 가지지만 아토피 피부염에 특화된 중증도 항목을 포함합니다.
EASI 계산 방법:
EASI도 신체를 4개 부위로 나누지만, 가중치가 PASI와 다릅니다 (소아의 경우 두부 비중이 높음):
| 신체 부위 | 성인 가중치 | 소아 (< 8세) 가중치 |
|---|---|---|
| 두부/경부 | 0.1 | 0.2 |
| 상지 | 0.2 | 0.2 |
| 체간 | 0.3 | 0.3 |
| 하지 | 0.4 | 0.3 |
중증도 평가 항목 (각 0-3점):
- 홍반 (Erythema): 0=없음, 1=경미, 2=중등, 3=심함
- 경화/구진 (Induration/Papulation): 0-3
- 찰과 (Excoriation): 0-3
- 태선화 (Lichenification): 0-3
면적 점수: PASI와 동일 (0-6점)
EASI 수식:
\[EASI = \sum_{i} w_i \times A_i \times (E_i + I_i + Ex_i + L_i)\]
- 최소값: 0
- 최대값: \(\sum w_i \times 6 \times 12 = 72\) (성인)
# EASI 계산 함수 구현
calculate_easi <- function(
head_area, head_erythema, head_induration, head_excoriation, head_lichenification,
upper_area, upper_erythema, upper_induration, upper_excoriation, upper_lichenification,
trunk_area, trunk_erythema, trunk_induration, trunk_excoriation, trunk_lichenification,
lower_area, lower_erythema, lower_induration, lower_excoriation, lower_lichenification,
pediatric = FALSE # 소아 여부
) {
# 가중치 설정
if (pediatric) {
w <- c(head = 0.2, upper = 0.2, trunk = 0.3, lower = 0.3)
} else {
w <- c(head = 0.1, upper = 0.2, trunk = 0.3, lower = 0.4)
}
# 각 부위 점수 계산
scores <- c(
w["head"] * head_area * (head_erythema + head_induration + head_excoriation + head_lichenification),
w["upper"] * upper_area * (upper_erythema + upper_induration + upper_excoriation + upper_lichenification),
w["trunk"] * trunk_area * (trunk_erythema + trunk_induration + trunk_excoriation + trunk_lichenification),
w["lower"] * lower_area * (lower_erythema + lower_induration + lower_excoriation + lower_lichenification)
)
easi <- sum(scores)
return(as.numeric(easi))
}
# 예시: 중등증-중증 아토피 피부염 환자
easi_example <- calculate_easi(
head_area = 2, head_erythema = 2, head_induration = 1, head_excoriation = 2, head_lichenification = 1,
upper_area = 3, upper_erythema = 2, upper_induration = 2, upper_excoriation = 2, upper_lichenification = 1,
trunk_area = 2, trunk_erythema = 2, trunk_induration = 1, trunk_excoriation = 1, trunk_lichenification = 1,
lower_area = 3, lower_erythema = 2, lower_induration = 2, lower_excoriation = 2, lower_lichenification = 2,
pediatric = FALSE
)
cat("EASI Score:", easi_example, "\n")EASI 중증도 분류:
| 분류 | EASI Score | 해석 |
|---|---|---|
| Clear/Almost Clear | 0-1.0 | 치료 목표 |
| Mild | 1.1-7.0 | 경증 |
| Moderate | 7.1-21.0 | 중등증 |
| Severe | 21.1-50.0 | 중증 |
| Very Severe | 50.1-72.0 | 매우 중증 |
11.2.3 SCORAD: SCORing Atopic Dermatitis
SCORAD는 아토피 피부염의 가장 종합적인 평가 도구로, 객관적 징후뿐만 아니라 환자의 주관적 증상도 포함합니다.
SCORAD 구성 요소:
\[SCORAD = \frac{A}{5} + \frac{7B}{2} + C\]
A: 면적 (Extent, 0-100)
- Rule of 9을 사용하여 전체 BSA 중 병변 비율 (%)을 산출
- 직접적인 면적 비율이므로 0-100 범위
B: 중증도 (Intensity, 0-18)
6가지 항목을 각각 0-3점으로 평가:
| 항목 | 0 | 1 | 2 | 3 |
|---|---|---|---|---|
| 홍반 (Erythema) | 없음 | 경미 | 중등 | 심함 |
| 부종/구진 (Edema/Papulation) | 없음 | 경미 | 중등 | 심함 |
| 삼출/가피 (Oozing/Crusting) | 없음 | 경미 | 중등 | 심함 |
| 찰과 (Excoriation) | 없음 | 경미 | 중등 | 심함 |
| 태선화 (Lichenification) | 없음 | 경미 | 중등 | 심함 |
| 건조 (Dryness) | 없음 | 경미 | 중등 | 심함 |
C: 주관적 증상 (Subjective Symptoms, 0-20)
환자가 직접 보고하는 두 가지 항목 (각 0-10 VAS):
- 소양증 (Pruritus): “지난 3일 동안 가려움의 정도”
- 수면 장애 (Sleep loss): “지난 3일 동안 수면 방해 정도”
SCORAD 범위: 0-103
| 분류 | SCORAD | 해석 |
|---|---|---|
| Mild | < 25 | 경증 |
| Moderate | 25-50 | 중등증 |
| Severe | > 50 | 중증 |
힌트o-SCORAD vs SCORAD
o-SCORAD (Objective SCORAD)는 주관적 증상(C 컴포넌트)을 제외한 점수입니다:
\[o\text{-}SCORAD = \frac{A}{5} + \frac{7B}{2}\]
범위: 0-83
PK-PD 모델링에서는 주관적 증상의 높은 변이성 때문에 o-SCORAD를 PD 엔드포인트로 사용하는 것이 선호되기도 합니다. 그러나 환자 관점에서 소양증은 아토피 피부염의 가장 고통스러운 증상이므로, 임상적으로는 SCORAD (주관적 증상 포함)이 더 종합적인 평가입니다.
11.2.4 IGA: Investigator’s Global Assessment
IGA는 평가자가 전반적인 질환 중증도를 단일 척도로 평가하는 도구입니다. 계산이 필요 없어 빠르고 간편하며, FDA에서 co-primary endpoint로 요구합니다.
IGA 5-Point Scale (건선, 아토피 피부염 공통):
| Score | 등급 | 건선 기준 | 아토피 피부염 기준 |
|---|---|---|---|
| 0 | Clear | 병변 없음, 색소침착만 가능 | 염증 없음, 색소침착만 가능 |
| 1 | Almost Clear | 정상 피부색, 경미한 인설 | 거의 정상, 미미한 홍반 |
| 2 | Mild | 약간의 홍반, 약간의 인설/비후 | 경미한 홍반, 경미한 경화/구진 |
| 3 | Moderate | 뚜렷한 홍반, 중등도 인설/비후 | 뚜렷한 홍반, 중등도 경화/구진 |
| 4 | Severe | 심한 홍반, 심한 인설/비후 | 심한 홍반, 심한 경화/구진 |
IGA의 장단점:
| 장점 | 단점 |
|---|---|
| 빠르고 간편한 평가 | 주관적이며 평가자 간 변이가 큼 |
| FDA 요구사항 충족 | 변화 감지 민감도가 낮음 (5점 척도) |
| 직관적 해석 | 부위별 차이를 반영하지 못함 |
| Responder definition 명확 (0/1) | 치료 시작 시 IGA 2인 환자 불리 |
11.2.5 DLQI: Dermatology Life Quality Index
DLQI는 환자 보고 결과(Patient-Reported Outcome, PRO)의 대표적 도구로, 피부 질환이 환자의 삶의 질에 미치는 영향을 평가합니다.
DLQI 구성: 10개 문항, 각 0-3점 (총 0-30점)
| 영역 | 문항 수 | 평가 내용 |
|---|---|---|
| 증상/감정 | 2 | 가려움, 따끔거림, 당혹감 |
| 일상 활동 | 2 | 쇼핑, 집안일, 옷 선택 |
| 여가 활동 | 2 | 스포츠, 사교 활동 |
| 직장/학교 | 1 | 업무/학업 방해 |
| 대인관계 | 2 | 파트너/친구/가족 관계, 성생활 |
| 치료 | 1 | 치료에 소요되는 시간/불편 |
DLQI 해석:
| DLQI Score | 해석 |
|---|---|
| 0-1 | 삶의 질에 영향 없음 (DLQI 0/1 = 치료 목표) |
| 2-5 | 약간의 영향 |
| 6-10 | 중등도 영향 |
| 11-20 | 큰 영향 |
| 21-30 | 매우 큰 영향 |
11.2.6 평가 도구 비교표
# 피부과 PD 평가 도구 비교표
pd_tools <- tibble(
도구 = c("PASI", "EASI", "SCORAD", "IGA", "DLQI", "Pruritus NRS"),
질환 = c("건선", "아토피 피부염", "아토피 피부염", "건선/AD 공통", "피부 질환 전반", "소양증"),
범위 = c("0-72", "0-72", "0-103", "0-4", "0-30", "0-10"),
유형 = c("연속형", "연속형", "연속형", "순서형", "연속형", "연속형"),
평가자 = c("의사", "의사", "의사+환자", "의사", "환자", "환자"),
규제기관_위치 = c("Primary/Co-primary", "Primary/Co-primary", "Secondary", "Co-primary", "Key secondary", "Key secondary"),
MCID = c("~5점", "~6.6점", "~8.7점", "≥1점 개선", "≥4점", "≥4점"),
장점 = c("Gold standard, 재현성 높음", "AD에 특화, 객관적", "종합적 (주관 포함)", "간편, FDA 요구", "환자 관점 반영", "환자 관점, 간편"),
단점 = c("계산 복잡, AD에 부적합", "태선화/삼출 미반영", "복잡한 계산, 주관 변이", "민감도 낮음", "문화적 차이", "주관적")
)
pd_tools %>%
gt() %>%
tab_header(
title = "피부과 PD 평가 도구 비교",
subtitle = "건선 및 아토피 피부염 임상시험에서 사용되는 주요 도구"
) %>%
cols_label(
도구 = "평가 도구",
규제기관_위치 = "규제기관 위치",
장점 = "장점",
단점 = "단점"
) %>%
tab_footnote(
footnote = "MCID: Minimal Clinically Important Difference (최소 임상적 유의 차이)",
locations = cells_column_labels(columns = MCID)
) %>%
tab_style(
style = cell_text(weight = "bold"),
locations = cells_column_labels()
)11.3 시간 경과에 따른 PD 변화
11.3.1 내성(Tolerance)과 Tachyphylaxis
내성(tolerance)은 약물에 반복적으로 노출될 때 같은 농도에서 효과가 점진적으로 감소하는 현상입니다. Tachyphylaxis는 특히 빠르게 발생하는 내성을 지칭합니다.
피부과에서의 내성 예시:
| 약물 | 내성 유형 | 발생 시기 | 기전 |
|---|---|---|---|
| 국소 스테로이드 | Tachyphylaxis | 수일-수주 | 수용체 하향조절, 피부 위축 |
| Cyclosporine | 내성 | 수개월 | T세포 적응, 신독성에 의한 용량 감소 |
| 생물학적 제제 | 이차 실패 (secondary failure) | 수개월-수년 | ADA 생성, 대체 면역경로 활성화 |
내성의 PK-PD 모델링:
내성을 모델에 포함하는 방법 중 하나는 time-varying tolerance compartment를 추가하는 것입니다:
\[\frac{dTOL}{dt} = k_{tol,in} \cdot C - k_{tol,out} \cdot TOL\]
\[E = \frac{E_{max} \cdot C^{\gamma}}{EC_{50}^{\gamma} \cdot (1 + TOL)^{\gamma} + C^{\gamma}}\]
이 모델에서 \(TOL\)이 증가하면 apparent \(EC_{50}\)이 증가하여 같은 농도에서 효과가 감소합니다.
11.3.2 반동(Rebound) 현상
반동(rebound)은 약물 중단 후 질환이 치료 전보다 더 악화되는 현상입니다. 피부과에서 가장 대표적인 예는 건선에서의 스테로이드 반동입니다.
건선의 스테로이드 반동:
- 전신 스테로이드 중단 후 generalized pustular psoriasis 유발 가능
- 강력한 국소 스테로이드의 갑작스러운 중단 후 국소 악화
- 기전: 스테로이드에 의한 면역 억제 해제 → 축적된 면역 반응의 급격한 방출
생물학적 제제의 반동:
| 약물 | 반동 | 비고 |
|---|---|---|
| TNF-α 억제제 | 드물게 보고 | 대부분 baseline 수준으로 복귀 |
| IL-17 억제제 | 매우 드물음 | 일부에서 treatment-emergent 건선 보고 |
| IL-23 억제제 | 거의 없음 | 긴 반감기로 인한 점진적 효과 소실 |
| Dupilumab | 거의 없음 | 중단 후 수주에 걸쳐 점진적 악화 |
# 반동 현상 시뮬레이션
# 약물 중단 후 baseline 이상으로 악화하는 시나리오
time_total <- seq(0, 40, by = 0.1) # weeks
# 시나리오 1: 반동 없음 (생물학적 제제)
baseline_1 <- 30 # EASI baseline
effect_on <- baseline_1 * exp(-0.15 * pmin(time_total, 16)) # 치료 중 개선
effect_off_no_rebound <- ifelse(
time_total > 16,
effect_on[time_total == 16] + (baseline_1 - effect_on[time_total == 16]) *
(1 - exp(-0.08 * (time_total[time_total > 16] - 16))),
effect_on
)
# 시나리오 2: 반동 있음 (스테로이드)
rebound_peak <- baseline_1 * 1.5 # baseline보다 50% 더 악화
effect_off_rebound <- ifelse(
time_total > 16,
effect_on[time_total == 16] +
(rebound_peak - effect_on[time_total == 16]) *
(1 - exp(-0.3 * (time_total[time_total > 16] - 16))) *
exp(-0.05 * (time_total[time_total > 16] - 16)),
effect_on
)
rebound_data <- tibble(
week = rep(time_total, 2),
easi = c(
ifelse(time_total <= 16, effect_on, effect_off_no_rebound),
ifelse(time_total <= 16, effect_on, effect_off_rebound)
),
scenario = rep(c("반동 없음 (Biologics)", "반동 있음 (Steroids)"), each = length(time_total))
)
ggplot(rebound_data, aes(x = week, y = easi, color = scenario)) +
geom_line(linewidth = 1) +
geom_vline(xintercept = 16, linetype = "dashed", color = "grey50") +
annotate("text", x = 16.5, y = 32, label = "약물 중단", hjust = 0, size = 3.5) +
geom_hline(yintercept = baseline_1, linetype = "dotted", color = "grey70") +
annotate("text", x = 0.5, y = baseline_1 + 1.5, label = "Baseline", size = 3.5, color = "grey50") +
labs(
x = "시간 (주)",
y = "EASI Score",
title = "약물 중단 후 반동 현상 비교",
color = "시나리오"
) +
theme_minimal(base_family = "NanumGothic") +
theme(
plot.title = element_text(face = "bold", size = 14),
legend.position = "bottom"
) +
scale_color_manual(values = c("steelblue", "coral"))11.3.3 지속적 반응 vs 감소하는 반응
장기 치료에서 약물 반응의 지속성(durability)은 중요한 고려사항입니다.
지속적 반응(Durable Response):
- 약물 투여를 지속하는 동안 효과가 유지 또는 개선
- IL-23 억제제(Risankizumab, Guselkumab): 52주 이상 높은 PASI90 달성률 유지
- 투여 간격 연장(dose spacing) 가능성
감소하는 반응(Waning Response, Secondary Failure):
- 초기에는 효과적이었던 약물의 효과가 시간이 지남에 따라 감소
- 원인:
- Anti-Drug Antibody (ADA): 약물에 대한 면역 반응으로 중화항체 생성
- 면역 경로 전환: 차단된 경로 대신 대체 경로 활성화
- 질환 진행: 기저 질환의 자연 진행
- TNF-α 억제제에서 가장 흔히 관찰 (Adalimumab: 약 30-40%에서 5년 내 이차 실패)
# 장기 치료 반응 패턴 시각화
weeks <- seq(0, 104, by = 1)
response_patterns <- tibble(
week = rep(weeks, 3),
pasi_improvement = c(
# 패턴 1: 지속적 반응 (IL-23 억제제)
90 * (1 - exp(-0.08 * weeks)),
# 패턴 2: 초기 반응 후 감소 (ADA 발생)
90 * (1 - exp(-0.08 * weeks)) * exp(-0.005 * pmax(weeks - 24, 0)),
# 패턴 3: 느린 반응, 지속 유지
70 * (1 - exp(-0.04 * weeks))
),
pattern = rep(c(
"지속적 고반응 (IL-23i)",
"이차 실패 (ADA 발생, TNFi)",
"느린 반응, 지속 유지"
), each = length(weeks))
)
ggplot(response_patterns, aes(x = week, y = pasi_improvement, color = pattern)) +
geom_line(linewidth = 1.2) +
geom_hline(yintercept = c(75, 90), linetype = "dashed", color = "grey50", alpha = 0.5) +
annotate("text", x = 2, y = 77, label = "PASI75", size = 3, color = "grey40") +
annotate("text", x = 2, y = 92, label = "PASI90", size = 3, color = "grey40") +
labs(
x = "시간 (주)",
y = "PASI % 개선",
title = "장기 치료 반응 패턴",
color = "반응 유형"
) +
scale_y_continuous(limits = c(0, 100)) +
theme_minimal(base_family = "NanumGothic") +
theme(
plot.title = element_text(face = "bold", size = 14),
legend.position = "bottom"
) +
scale_color_manual(values = c("coral", "steelblue", "darkgreen"))11.4 R 실습
11.4.1 Baseline 보정 함수 구현
# 범용 Baseline 보정 함수
correct_baseline <- function(data,
id_col = "subject_id",
time_col = "week",
value_col = "score",
baseline_time = 0,
method = c("absolute", "percent", "ratio")) {
method <- match.arg(method)
# Baseline 값 추출
baseline_values <- data %>%
filter(.data[[time_col]] == baseline_time) %>%
select(all_of(c(id_col, value_col))) %>%
rename(baseline = all_of(value_col))
# Baseline과 병합
result <- data %>%
left_join(baseline_values, by = id_col)
# 보정 방법에 따라 계산
result <- result %>%
mutate(
corrected = case_when(
method == "absolute" ~ .data[[value_col]] - baseline,
method == "percent" ~ (.data[[value_col]] - baseline) / baseline * 100,
method == "ratio" ~ .data[[value_col]] / baseline
)
)
return(result)
}
# 모의 PD 데이터 생성
set.seed(123)
n_subjects <- 60
n_weeks <- c(0, 2, 4, 8, 12, 16)
pd_data <- expand_grid(
subject_id = 1:n_subjects,
week = n_weeks
) %>%
mutate(
treatment = rep(
rep(c("Drug 300mg", "Drug 100mg", "Placebo"), each = 20),
times = length(n_weeks)
)
) %>%
group_by(subject_id) %>%
mutate(
# Baseline EASI (moderate to severe)
baseline_easi = rnorm(1, mean = 28, sd = 8) %>% pmax(16) %>% pmin(50),
# Treatment effect
easi_score = case_when(
week == 0 ~ baseline_easi,
treatment == "Drug 300mg" ~ baseline_easi * exp(-0.12 * week) + rnorm(n(), 0, 3),
treatment == "Drug 100mg" ~ baseline_easi * exp(-0.06 * week) + rnorm(n(), 0, 3),
treatment == "Placebo" ~ baseline_easi * exp(-0.015 * week) + rnorm(n(), 0, 4)
),
easi_score = pmax(easi_score, 0)
) %>%
ungroup()
# 각 보정 방법 적용
pd_absolute <- correct_baseline(pd_data, value_col = "easi_score", method = "absolute")
pd_percent <- correct_baseline(pd_data, value_col = "easi_score", method = "percent")
pd_ratio <- correct_baseline(pd_data, value_col = "easi_score", method = "ratio")
# 세 가지 보정 결과 비교 시각화
p_abs <- pd_absolute %>%
group_by(treatment, week) %>%
summarise(mean_change = mean(corrected), se = sd(corrected) / sqrt(n()), .groups = "drop") %>%
ggplot(aes(x = week, y = mean_change, color = treatment)) +
geom_line(linewidth = 0.8) +
geom_point(size = 2) +
geom_errorbar(aes(ymin = mean_change - se, ymax = mean_change + se), width = 0.5) +
geom_hline(yintercept = 0, linetype = "dashed") +
labs(x = "주 (Week)", y = "EASI 절대 변화", title = "Absolute Change") +
theme_minimal(base_family = "NanumGothic") +
theme(legend.position = "none")
p_pct <- pd_percent %>%
group_by(treatment, week) %>%
summarise(mean_change = mean(corrected), se = sd(corrected) / sqrt(n()), .groups = "drop") %>%
ggplot(aes(x = week, y = mean_change, color = treatment)) +
geom_line(linewidth = 0.8) +
geom_point(size = 2) +
geom_errorbar(aes(ymin = mean_change - se, ymax = mean_change + se), width = 0.5) +
geom_hline(yintercept = -75, linetype = "dashed", color = "red", alpha = 0.5) +
annotate("text", x = 1, y = -72, label = "EASI-75", color = "red", size = 3) +
labs(x = "주 (Week)", y = "EASI % 변화", title = "Percent Change") +
theme_minimal(base_family = "NanumGothic") +
theme(legend.position = "none")
p_ratio <- pd_ratio %>%
group_by(treatment, week) %>%
summarise(mean_change = mean(corrected), se = sd(corrected) / sqrt(n()), .groups = "drop") %>%
ggplot(aes(x = week, y = mean_change, color = treatment)) +
geom_line(linewidth = 0.8) +
geom_point(size = 2) +
geom_errorbar(aes(ymin = mean_change - se, ymax = mean_change + se), width = 0.5) +
geom_hline(yintercept = 1, linetype = "dashed") +
labs(x = "주 (Week)", y = "EASI Ratio", title = "Ratio to Baseline") +
theme_minimal(base_family = "NanumGothic") +
theme(legend.position = "bottom") +
scale_color_manual(values = c("steelblue", "darkgreen", "grey50"))
(p_abs + p_pct + p_ratio) + plot_annotation(
title = "Baseline 보정 방법 비교",
theme = theme(plot.title = element_text(face = "bold", size = 14))
)11.4.2 PASI/EASI Score 변화량 계산 및 시각화
# PASI score 시간 경과 데이터 (모의)
set.seed(456)
n_pts <- 120
timepoints <- c(0, 4, 8, 12, 16, 24, 52)
pasi_data <- expand_grid(
patient_id = 1:n_pts,
week = timepoints
) %>%
mutate(
treatment = rep(
rep(c("Biologics A", "Biologics B", "Placebo"), each = 40),
times = length(timepoints)
)
) %>%
group_by(patient_id) %>%
mutate(
baseline_pasi = rnorm(1, 20, 6) %>% pmax(12) %>% pmin(40),
pasi = case_when(
week == 0 ~ baseline_pasi,
treatment == "Biologics A" ~ baseline_pasi * exp(-0.08 * week) * (1 + rnorm(1, 0, 0.1)),
treatment == "Biologics B" ~ baseline_pasi * exp(-0.05 * week) * (1 + rnorm(1, 0, 0.12)),
treatment == "Placebo" ~ baseline_pasi * (1 - 0.003 * week) + rnorm(1, 0, 2)
),
pasi = pmax(pasi, 0),
pasi_pct_change = (pasi - baseline_pasi) / baseline_pasi * 100
) %>%
ungroup()
# Mean ± SE by treatment group (Time-course PD 그래프)
pasi_summary <- pasi_data %>%
group_by(treatment, week) %>%
summarise(
n = n(),
mean_change = mean(pasi_pct_change),
se = sd(pasi_pct_change) / sqrt(n()),
.groups = "drop"
)
p_timecourse <- ggplot(pasi_summary, aes(x = week, y = mean_change, color = treatment)) +
geom_line(linewidth = 1) +
geom_point(size = 2.5) +
geom_errorbar(
aes(ymin = mean_change - se, ymax = mean_change + se),
width = 0.8, linewidth = 0.5
) +
geom_hline(yintercept = c(-75, -90), linetype = "dashed", color = "grey50", alpha = 0.5) +
annotate("text", x = 53, y = -73, label = "PASI75", size = 3, color = "grey40", hjust = 1) +
annotate("text", x = 53, y = -88, label = "PASI90", size = 3, color = "grey40", hjust = 1) +
labs(
x = "시간 (주)",
y = "PASI % Change from Baseline (Mean ± SE)",
title = "PASI Score 시간 경과: Mean ± SE by Treatment Group",
color = "치료군"
) +
scale_y_continuous(limits = c(-100, 20), breaks = seq(-100, 20, by = 20)) +
theme_minimal(base_family = "NanumGothic") +
theme(
plot.title = element_text(face = "bold", size = 13),
legend.position = "bottom"
) +
scale_color_manual(values = c("steelblue", "coral", "grey50"))
print(p_timecourse)11.4.3 PASI75/90/100 달성률 계산
# Responder rate 계산
responder_data <- pasi_data %>%
filter(week > 0) %>%
mutate(
pasi75 = pasi_pct_change <= -75,
pasi90 = pasi_pct_change <= -90,
pasi100 = pasi <= 0.5 # PASI ≈ 0
)
# 시점별/치료군별 달성률 계산
responder_summary <- responder_data %>%
group_by(treatment, week) %>%
summarise(
n = n(),
pasi75_rate = mean(pasi75) * 100,
pasi90_rate = mean(pasi90) * 100,
pasi100_rate = mean(pasi100) * 100,
.groups = "drop"
)
# PASI75 달성률 시간 경과 그래프
p_pasi75_rate <- ggplot(responder_summary, aes(x = week, y = pasi75_rate, color = treatment)) +
geom_line(linewidth = 1) +
geom_point(size = 2.5) +
labs(
x = "시간 (주)",
y = "PASI75 달성률 (%)",
title = "PASI75 Responder Rate over Time",
color = "치료군"
) +
scale_y_continuous(limits = c(0, 100), breaks = seq(0, 100, by = 20)) +
theme_minimal(base_family = "NanumGothic") +
theme(
plot.title = element_text(face = "bold", size = 13),
legend.position = "bottom"
) +
scale_color_manual(values = c("steelblue", "coral", "grey50"))
# 12주차 PASI75/90/100 달성률 비교 막대 그래프
week12_data <- responder_summary %>%
filter(week == 12) %>%
pivot_longer(
cols = c(pasi75_rate, pasi90_rate, pasi100_rate),
names_to = "endpoint",
values_to = "rate"
) %>%
mutate(
endpoint = case_when(
endpoint == "pasi75_rate" ~ "PASI75",
endpoint == "pasi90_rate" ~ "PASI90",
endpoint == "pasi100_rate" ~ "PASI100"
),
endpoint = factor(endpoint, levels = c("PASI75", "PASI90", "PASI100"))
)
p_week12_bar <- ggplot(week12_data, aes(x = endpoint, y = rate, fill = treatment)) +
geom_col(position = position_dodge(width = 0.7), width = 0.6, alpha = 0.85) +
geom_text(
aes(label = paste0(round(rate), "%")),
position = position_dodge(width = 0.7),
vjust = -0.5, size = 3.5
) +
labs(
x = "엔드포인트",
y = "달성률 (%)",
title = "12주차 PASI 반응률 비교",
fill = "치료군"
) +
scale_y_continuous(limits = c(0, 110)) +
theme_minimal(base_family = "NanumGothic") +
theme(
plot.title = element_text(face = "bold", size = 13),
legend.position = "bottom"
) +
scale_fill_manual(values = c("steelblue", "coral", "grey50"))
p_pasi75_rate + p_week12_bar# gt 테이블로 responder rate 요약
responder_summary %>%
filter(week %in% c(4, 12, 24, 52)) %>%
gt(groupname_col = "treatment") %>%
tab_header(
title = "PASI Responder Rate Summary",
subtitle = "치료군별, 시점별 반응률 (%)"
) %>%
cols_label(
week = "주차",
n = "N",
pasi75_rate = "PASI75 (%)",
pasi90_rate = "PASI90 (%)",
pasi100_rate = "PASI100 (%)"
) %>%
fmt_number(columns = c(pasi75_rate, pasi90_rate, pasi100_rate), decimals = 1) %>%
tab_style(
style = cell_text(weight = "bold"),
locations = cells_row_groups()
)11.4.4 Categorical Outcome 분석: Logistic Regression
IGA 0/1 달성 여부를 약물 노출과 연결하는 logistic regression 분석을 수행합니다.
# IGA 데이터 모의 생성
set.seed(789)
n_iga <- 200
iga_data <- tibble(
patient_id = 1:n_iga,
treatment = sample(c("Active", "Placebo"), n_iga, replace = TRUE, prob = c(0.7, 0.3)),
# 약물 노출 (AUC at Week 16, 로그정규분포)
auc = case_when(
treatment == "Active" ~ rlnorm(n_iga, log(500), 0.5),
TRUE ~ rlnorm(n_iga, log(1), 0.5) # Placebo: very low
),
baseline_iga = sample(3:4, n_iga, replace = TRUE, prob = c(0.6, 0.4)),
weight = rnorm(n_iga, 75, 15) %>% pmax(40)
) %>%
mutate(
# IGA 0/1 확률: AUC 의존적 + baseline + weight 영향
log_odds = -3 + 1.5 * log10(auc) - 0.5 * (baseline_iga - 3) - 0.01 * (weight - 75),
prob_iga01 = 1 / (1 + exp(-log_odds)),
iga_01 = rbinom(n_iga, 1, prob_iga01),
iga_01_label = ifelse(iga_01 == 1, "IGA 0/1 달성", "미달성"),
auc_quartile = cut(
auc, breaks = quantile(auc, c(0, 0.25, 0.5, 0.75, 1)),
labels = c("Q1", "Q2", "Q3", "Q4"), include.lowest = TRUE
)
)
# Logistic regression
model_iga <- glm(
iga_01 ~ log(auc) + factor(baseline_iga) + weight,
data = iga_data %>% filter(treatment == "Active"),
family = binomial
)
# 모델 결과 요약
tidy(model_iga, conf.int = TRUE, exponentiate = TRUE) %>%
gt() %>%
tab_header(
title = "IGA 0/1 달성에 대한 Logistic Regression",
subtitle = "Odds Ratio (95% CI)"
) %>%
fmt_number(columns = c(estimate, conf.low, conf.high), decimals = 3) %>%
fmt_number(columns = p.value, decimals = 4)# 노출-반응 곡선 (Predicted probability vs AUC)
auc_pred <- tibble(
auc = seq(10, 3000, length.out = 200),
baseline_iga = 3,
weight = 75
)
auc_pred$predicted <- predict(model_iga, newdata = auc_pred, type = "response")
p_logistic <- ggplot() +
# 개별 데이터 (jittered)
geom_jitter(
data = iga_data %>% filter(treatment == "Active"),
aes(x = auc, y = iga_01, color = iga_01_label),
width = 0, height = 0.05, alpha = 0.4, size = 2
) +
# 예측 곡선
geom_line(data = auc_pred, aes(x = auc, y = predicted),
linewidth = 1.2, color = "black") +
# 50% 확률 기준선
geom_hline(yintercept = 0.5, linetype = "dashed", color = "grey50") +
scale_x_log10(labels = scales::label_number()) +
labs(
x = expression(AUC[ss]~"(μg·day/mL, log scale)"),
y = "IGA 0/1 달성 확률",
title = "노출-반응 분석: AUC vs IGA 0/1 달성",
subtitle = "Logistic Regression (baseline IGA = 3, weight = 75kg 기준)",
color = ""
) +
theme_minimal(base_family = "NanumGothic") +
theme(
plot.title = element_text(face = "bold", size = 13),
legend.position = "bottom"
) +
scale_color_manual(values = c("coral", "steelblue"))
print(p_logistic)11.4.5 Forest Plot: Treatment Differences
# Forest plot 데이터: 여러 엔드포인트별 치료 차이
forest_data <- tibble(
endpoint = c("EASI-75", "EASI-90", "IGA 0/1", "Pruritus NRS ≥4",
"DLQI 0/1", "EASI absolute change", "SCORAD % change"),
estimate = c(36, 28, 26, 30, 22, -12.5, -35),
lower = c(28, 20, 18, 22, 14, -15.5, -42),
upper = c(44, 36, 34, 38, 30, -9.5, -28),
type = c(rep("Binary (%p)", 5), "Continuous", "Continuous")
) %>%
mutate(
endpoint = factor(endpoint, levels = rev(endpoint)),
label = paste0(
ifelse(type == "Binary (%p)",
paste0(estimate, "%p (", lower, ", ", upper, ")"),
paste0(estimate, " (", lower, ", ", upper, ")"))
)
)
# Forest plot (이분형 엔드포인트)
p_forest_binary <- forest_data %>%
filter(type == "Binary (%p)") %>%
ggplot(aes(x = estimate, y = endpoint)) +
geom_vline(xintercept = 0, linetype = "dashed", color = "grey50") +
geom_errorbarh(aes(xmin = lower, xmax = upper), height = 0.2, linewidth = 0.8) +
geom_point(size = 3, color = "steelblue") +
geom_text(aes(label = label, x = upper + 2), hjust = 0, size = 3.5) +
labs(
x = "Drug - Placebo (%p)",
y = "",
title = "Forest Plot: Treatment Difference (Drug vs Placebo)",
subtitle = "Binary endpoints at Week 16"
) +
scale_x_continuous(limits = c(-5, 55)) +
theme_minimal(base_family = "NanumGothic") +
theme(
plot.title = element_text(face = "bold", size = 13),
panel.grid.major.y = element_blank()
)
print(p_forest_binary)11.4.6 Kaplan-Meier: Time-to-PASI75
# Time-to-PASI75 데이터 생성
set.seed(321)
n_surv <- 180
surv_data <- tibble(
patient_id = 1:n_surv,
treatment = rep(c("Biologics A", "Biologics B", "Placebo"), each = 60)
) %>%
mutate(
# Time to PASI75 (weeks) - Weibull distribution
time_to_pasi75 = case_when(
treatment == "Biologics A" ~ rweibull(n_surv, shape = 2, scale = 10),
treatment == "Biologics B" ~ rweibull(n_surv, shape = 1.8, scale = 16),
treatment == "Placebo" ~ rweibull(n_surv, shape = 1.2, scale = 80)
),
# 관찰 기간 제한 (52주)
censored = time_to_pasi75 > 52,
time_obs = pmin(time_to_pasi75, 52),
event = as.numeric(!censored)
)
# Kaplan-Meier 분석
km_fit <- survfit(Surv(time_obs, event) ~ treatment, data = surv_data)
# survminer를 사용한 KM 곡선
p_km <- ggsurvplot(
km_fit,
data = surv_data,
pval = TRUE,
conf.int = TRUE,
risk.table = TRUE,
risk.table.col = "strata",
palette = c("steelblue", "coral", "grey50"),
xlab = "시간 (주)",
ylab = "PASI75 미달성 확률",
title = "Kaplan-Meier: Time to PASI75",
legend.title = "치료군",
ggtheme = theme_minimal(base_family = "NanumGothic"),
break.time.by = 8
)
print(p_km)# 중앙 생존시간 (Median time to PASI75)
km_median <- surv_median(km_fit) %>%
as_tibble()
km_median %>%
gt() %>%
tab_header(
title = "PASI75 달성까지의 중앙 시간 (Median Time to PASI75)",
subtitle = "Kaplan-Meier 분석 결과"
) %>%
cols_label(
strata = "치료군",
median = "중앙값 (주)",
`0.95LCL` = "95% CI 하한",
`0.95UCL` = "95% CI 상한"
) %>%
fmt_number(columns = c(median, `0.95LCL`, `0.95UCL`), decimals = 1) %>%
tab_footnote("관찰 기간 52주, 중도절단(censoring) 반영")# Log-rank test
logrank_test <- survdiff(Surv(time_obs, event) ~ treatment, data = surv_data)
cat("Log-rank test\n")
cat("Chi-squared:", round(logrank_test$chisq, 2), "\n")
cat("p-value:", format.pval(pchisq(logrank_test$chisq, df = 2, lower.tail = FALSE)), "\n")
# Cox proportional hazards model
cox_model <- coxph(Surv(time_obs, event) ~ treatment, data = surv_data)
tidy(cox_model, conf.int = TRUE, exponentiate = TRUE) %>%
gt() %>%
tab_header(
title = "Cox Proportional Hazards Model: Time to PASI75",
subtitle = "Hazard Ratio (Reference: Biologics A)"
) %>%
fmt_number(columns = c(estimate, conf.low, conf.high), decimals = 2) %>%
fmt_number(columns = p.value, decimals = 4)11.5 약리학 노트: 건선과 아토피 피부염의 PD 엔드포인트 비교
11.5.1 건선의 PD 엔드포인트 체계
건선 임상시험에서의 엔드포인트 요구사항은 비교적 확립되어 있으며, 생물학적 제제의 발전과 함께 더 높은 기준으로 진화하고 있습니다.
FDA 요구사항 (건선):
- Co-primary endpoints (두 가지 모두 충족):
- PASI75 (또는 최근에는 PASI90) at primary timepoint
- IGA 0/1 at primary timepoint
- Primary timepoint: 일반적으로 12주 또는 16주
- 분석 방법: NRI (Non-Responder Imputation) for primary
EMA 요구사항 (건선):
- Primary: PASI75 at Week 12-16
- Co-primary: IGA 0/1은 필수는 아니지만 강력히 권장
- 장기 효과: 52주 이상의 유지 요법(maintenance therapy) 데이터 요구
- 분석 방법: MMRM 또는 MI 선호, NRI는 sensitivity analysis
주요 약물의 건선 엔드포인트 결과:
| 약물 (기전) | PASI75 (12-16주) | PASI90 (12-16주) | IGA 0/1 (12-16주) |
|---|---|---|---|
| Adalimumab (TNFi) | 71% | 40% | 62% |
| Secukinumab (IL-17A) | 82% | 59% | 65% |
| Ixekizumab (IL-17A) | 90% | 71% | 73% |
| Guselkumab (IL-23) | 91% | 73% | 85% |
| Risankizumab (IL-23) | 91% | 75% | 84% |
| Bimekizumab (IL-17A/F) | 93% | 79% | 77% |
노트건선 치료의 패러다임 변화
위 표에서 볼 수 있듯이, 최신 생물학적 제제(IL-23 억제제, 이중 IL-17 억제제)는 PASI90 달성률이 70-80%에 달합니다. 이는 과거 “PASI75가 훌륭한 결과”였던 시대에서 “피부 완전 관해(complete clearance)”를 현실적 목표로 설정할 수 있는 시대로의 전환을 의미합니다.
이러한 변화는 PK-PD 모델링에도 영향을 미칩니다. 효과 크기가 매우 클 때(ceiling effect), 전통적인 Emax 모델에서 파라미터 추정이 어려울 수 있으며, logistic regression 기반의 노출-반응 분석이 더 실용적일 수 있습니다.
11.5.2 아토피 피부염의 PD 엔드포인트 체계
아토피 피부염은 건선에 비해 PD 엔드포인트의 표준화가 덜 되어 있으며, 최근 급격히 발전하고 있는 분야입니다.
FDA 요구사항 (아토피 피부염):
- Co-primary endpoints (두 가지 모두 충족):
- IGA 0/1 AND baseline에서 ≥2점 개선
- EASI-75
- Primary timepoint: 16주
- Population: 중등증-중증 (IGA ≥3, EASI ≥16, BSA ≥10%)
- 분석 방법: NRI for primary, MMRM for supportive
EMA 요구사항 (아토피 피부염):
- Primary: EASI-75 또는 IGA 0/1 (하나가 primary, 나머지가 key secondary)
- 장기 데이터: 52주 연장 시험 필수
- SCORAD: secondary endpoint으로 권장
- PROs (DLQI, Pruritus NRS): 환자 관점 데이터 중요시
건선과 아토피 피부염 엔드포인트 비교:
| 측면 | 건선 | 아토피 피부염 |
|---|---|---|
| Gold standard | PASI | EASI |
| Co-primary | PASI + IGA | EASI-75 + IGA 0/1 (≥2점 개선) |
| Placebo response | 낮음 (3-5%) | 높음 (10-25%) |
| Scoring 범위 | 0-72 (PASI) | 0-72 (EASI) |
| 주관적 요소 | PASI에 없음 | SCORAD에 포함 |
| PRO | DLQI (secondary) | DLQI + Pruritus NRS (key secondary) |
| 평가 시점 | 12-16주 | 16주 |
| 유지 요법 평가 | 52주 | 52주 |
| Wash-out 설계 | 가능 (재발 연구) | 윤리적 이슈로 제한적 |
중요엔드포인트 선택이 PK-PD 분석에 미치는 영향
PK-PD 모델링에서 엔드포인트의 선택은 모델 구조와 해석에 직접적인 영향을 미칩니다:
- 연속형 (EASI, PASI): Emax 또는 IDR 모델에 직접 연결 가능, 파라미터 추정 효율 높음
- 이분형 (PASI75, IGA 0/1): Logistic regression 필요, 정보 손실 있음, 그러나 규제기관이 요구
- 순서형 (IGA 0-4): Proportional odds model, 5개 범주 모두 활용
- 시간-사건 (Time to PASI75): Cox model 또는 parametric hazard, PK가 시간 변동 공변량
최적의 접근은 연속형 데이터로 모델을 구축하고, 이를 기반으로 이분형 엔드포인트를 시뮬레이션으로 예측하는 것입니다. 예를 들어, EASI score의 IDR 모델을 구축한 후, EASI-75 달성 확률을 모델 기반으로 예측할 수 있습니다.
11.6 Claude Code 활용 팁
11.6.1 복잡한 Baseline 보정 로직
여러 가지 baseline 보정 방법을 동시에 적용하고 비교할 때:
"아토피 피부염 임상시험 데이터가 있어.
컬럼: subject_id, visit_week (0, 2, 4, 8, 12, 16),
treatment (Drug A, Drug B, Placebo), easi_score, iga_score
다음 분석을 수행해줘:
1. Baseline (week 0) 기준 EASI의 absolute change, percent change, ratio 계산
2. 각 치료군별 Mean ± SE time-course 그래프 (3가지 보정 방법 비교)
3. EASI-75 달성률을 시점별로 계산하고 그래프로 표시
4. IGA 0/1 달성 AND baseline에서 ≥2점 개선 비율 계산
5. NRI (결측 = 비반응)와 Observed case 분석 비교
6. 모든 결과를 gt 테이블로 요약
결측 데이터는 약 15%이며, 주로 약물 부작용이나 효과 부족으로
인한 중도탈락이야. NRI 적용 시 이 환자들을 비반응으로 처리해줘."11.6.2 PD 분석 보고서 자동화
"건선 Phase III 시험의 PD 분석 보고서를 자동으로 생성하는
R 함수를 만들어줘.
입력: PASI 데이터 (long format), 치료군 정보, 시점 정보
출력 (Quarto format):
1. 인구통계학적 요약 (gtsummary)
2. Baseline PASI 분포 (히스토그램 + 치료군별 비교)
3. PASI % change time-course (Mean ± SE, by treatment)
4. PASI75/90/100 달성률 테이블 및 그래프
5. IGA 0/1 달성률
6. Waterfall plot (16주차 개인별 반응)
7. Subgroup analysis (체중, 성별, baseline 중증도별)
8. Forest plot of treatment differences
모든 그래프는 출판 품질로, 한글 폰트 지원하고,
gt 테이블은 FDA 제출 형식에 맞춰줘."11.6.3 Exposure-Response 보고서
"Dupilumab의 노출-반응 분석을 위한 종합 R 스크립트를 작성해줘.
데이터: 환자별 Ctrough (Week 4, 8, 12, 16), EASI score, IGA score,
baseline 공변량 (체중, 나이, 성별, baseline EASI)
분석 내용:
1. Ctrough quartile별 EASI-75 달성률 (bar plot + 95% CI)
2. Ctrough vs EASI % change (scatter + LOESS)
3. Logistic regression: IGA 0/1 ~ log(Ctrough) + baseline covariates
4. Odds ratio forest plot
5. Predicted probability curves (체중 50/75/100kg)
6. ROC curve와 optimal cutoff for Ctrough
7. 모든 결과를 하나의 Quarto 보고서로 통합"11.7 연습 문제
11.7.1 확인 문제
PD 데이터의 baseline 보정에서 절대 변화(absolute change)와 백분율 변화(percent change)의 장단점을 비교하고, PASI 엔드포인트에서 percent change가 선호되는 이유를 설명하세요.
피부과 임상시험에서 placebo 반응이 발생하는 5가지 원인을 나열하고, 아토피 피부염의 placebo response가 건선보다 높은 이유를 추론하세요.
NRI (Non-Responder Imputation)와 MMRM (Mixed Model Repeated Measures)의 차이점을 설명하고, FDA와 EMA가 각각 어떤 방법을 선호하는지, 그 이유와 함께 설명하세요.
PASI와 EASI의 계산 방법을 비교하고, PASI에는 있지만 EASI에는 없는 중증도 항목과 EASI에만 있는 항목을 각각 설명하세요. 이 차이가 질환의 병태생리 차이를 어떻게 반영하는지 논의하세요.
IGA가 co-primary endpoint로 요구되는 이유와, IGA의 한계점 3가지를 설명하세요. IGA 기준에서 baseline IGA가 3인 환자가 4인 환자보다 불리한 이유를 계산과 함께 설명하세요.
11.7.2 R 과제
Baseline 보정 비교 분석: 이 장의 모의 PD 데이터를 사용하여 4가지 baseline 보정 방법(absolute change, percent change, ratio, ANCOVA)을 모두 적용하세요. 각 방법에서 치료군 간 차이(Drug vs Placebo)의 p-value와 effect size를 16주차에서 계산하고, 어떤 방법이 가장 검정력(power)이 높은지 비교하세요. 결과를 gt 테이블과 그래프로 정리하세요.
종합 PD 분석 파이프라인: 모의 PASI 데이터(3군, 52주)에 대해 다음을 수행하세요:
- PASI % change time-course 그래프 (Mean ± SE)
- PASI75/90/100 달성률 시점별 테이블 및 그래프
- 12주차 Waterfall plot (개인별 반응 막대그래프)
- Time-to-PASI75의 Kaplan-Meier 곡선 및 log-rank test
- 모든 결과를 하나의 종합 그래프(patchwork)로 조합
IGA Logistic Regression 분석: 모의 IGA 데이터를 생성하고, 16주차 IGA 0/1 달성에 대한 다음 분석을 수행하세요:
- 단변량 logistic regression: 각 공변량(AUC, 체중, 성별, baseline IGA)의 OR
- 다변량 logistic regression: 유의한 공변량을 포함한 최종 모델
- Odds Ratio Forest Plot
- AUC quartile별 IGA 0/1 달성률 막대 그래프
- Predicted probability curve (AUC vs IGA 0/1 확률)
11.7.3 Claude Code 과제
Claude Code에 다음과 같이 요청하세요: > “아토피 피부염 Phase III 시험의 모의 데이터를 생성하고, 완전한 PD 분석 보고서를 작성해줘. 300명의 환자 (Drug 200명, Placebo 100명), 16주 시험이야. EASI score (baseline 평균 25, SD 8), IGA score (baseline 3 또는 4), Pruritus NRS (baseline 평균 7, SD 1.5)를 포함해줘. 15%의 중도탈락률을 적용하되, 약물군보다 placebo군에서 탈락이 더 많게 해줘. NRI와 Observed case 분석을 모두 수행하고, primary endpoint (EASI-75 + IGA 0/1) 달성률, key secondary endpoint 분석, subgroup analysis (체중 ≤75kg vs >75kg), Kaplan-Meier (Time to EASI-50), 그리고 모든 결과를 포함한 종합 보고서를 Quarto 형식으로 만들어줘.”
결과 보고서에서 NRI와 Observed case 분석의 차이를 비교하고, 어떤 분석이 더 보수적인지 설명하세요.